
文章目录
1. 沟通模型
a. 一对一
- Unicast
- 1←→1
- 点对点
- Anycast
- 1→1 of several identical nodes
- 引入 ipv6, BGP 路由协议
b. 一对多
- 多播 Multicast
- 1 → many
- 群组通信
- 广播
- 1 → all
2. 设计问题
a. Closed vs. Open?:Closed:只有组内成员才能发送消息
b. 端 vs. 层次化(Peer vs. Hierarchical)
– 端:每个成员和整个组通信
– 层次化:通过协调者(coordinators)
– 根协调者:将消息转发给何时的子组协调者
c. 成员管理(Managing membership)& 组创建/删除:分布式(distributed)vs. 中心化的(centralized)
d. 离开(leave)和加入(join) 必须被同步(synchronize)
e. 错误容忍:可靠性的消息传输?若丢失怎么办?
3. 关于错误的思考(Failure consideration)
a. 崩溃失效 crash failure: 进程停止沟通
b. 遗漏失效 omission failure
- 通常归咎于网络
- 发送遗漏
- 接收遗漏
c. 拜占庭失效 Byzantine failure:某些消息错误了
d. 分区错误 Partition failure:网络被分割(segmented),分为了两个或者多个不可达的子组
4. 组播通信机制(Mechanisms)的实现
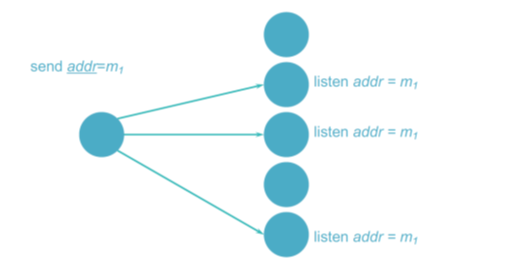
a. 硬件组播
- 如果硬件支持组播
- 组成员监听网络地址

- 广播
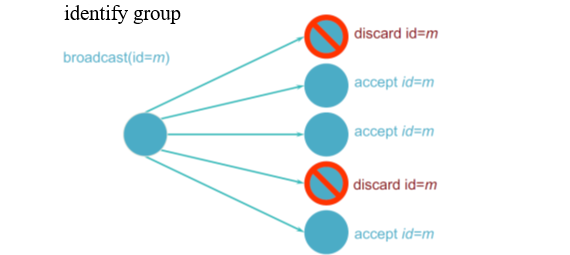
- 扩散组(diffusion group):发送给所有客户端 & 接着过滤
- 软件过滤器输入多播地址
- 很多使用辅助(auxiliary,not in the network address header)来鉴别组
- 扩散组(diffusion group):发送给所有客户端 & 接着过滤
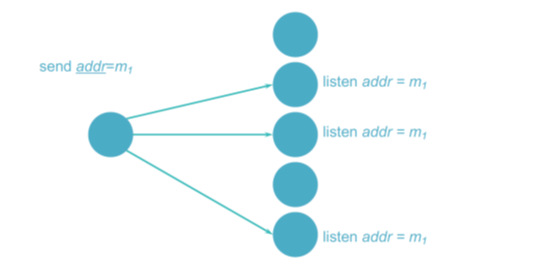
- 硬件多播
- 如果有支持多播的硬件
- 组成员会监听网络地址
- 如果有支持多播的硬件
- 总结:
- 以太网既支持多播也支持广播
- 限制在局域网
b. 软件实现
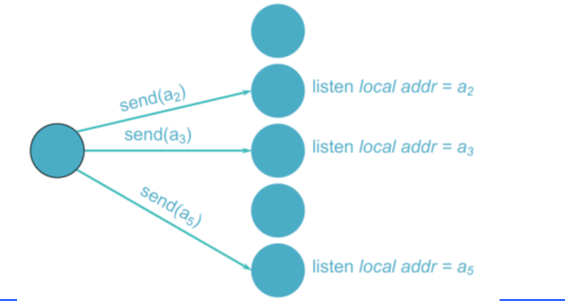
- 多路单播:发送者了解组成员
- 层次化:
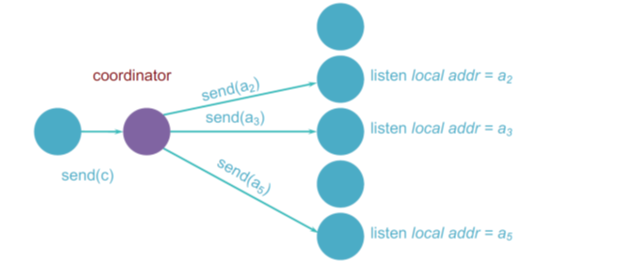
- 设计:通过组协调者的多个单播
- 协调者了解组成员
- 协调者在组成员之中迭代
- 可能支持层次化的协调者
- 图示:
- 设计:通过组协调者的多个单播
5. 多播的可靠性
a. 原子性(atomic)多播
- 原子性:
- 消息发送到一个组,会到达所有成员
- 如果它没有到达任意成员,则没有成员会处理它
- 问题:
- 不可靠的网络
- 每个消息都需要被确认
- 确认(acknowledgements)可能会丢失
- 消息发送方可能失效
- 不可靠的网络
b. 实现原子性
i. 基本概念
- 确保每个接受者(recipient)对消息的确认收据(receipt),惟其如此,应用才能处理消息
- 若放弃了任何收据,将没有接受者处理消息
ii. 易说难做:
- 如果接受者死亡在确认消息之前,该怎么办?
- 是否有义务(obligated)重启?
- 如果重启,它仍然知道处理这个消息吗?
- 若发送者或者协调者在协议中途死亡?
iii. 案例:
案例一:在网络失效或者系统停机(system downtime)时重试(retry)
- 发送方或者接收方应该维护一份持久性的志记
- 每个消息会被标记为唯一性的ID,来丢弃(discard)重复
- 发送方:
- 发送消息给所有组员
- 向日志中写消息
- 等待每一个组成员的确认
- 向日志中写确认
- 当等待确认消息超时的时候,向组员重传
- 接收方:
- 向持久性日志中志记非重复消息
- 发送确认
- 从不放弃:假设死去的发送者和接受者会在其离开处重启
ii. 案例二:组的重定义:
- 若有某些成员在接收消息时失败:
- 从组中移除失败的节点
- 允许存在的节点处理消息
- 但是仍然需要考虑(account for)死去的发送者:
- 存活的组成员需要接管(take over)来确保所有的现存成员会接收到消息
- 这是在虚同步(virtual synchrony)中使用的方法
iv. 可靠性多播:
- 任何非失效的组成员都会接受到消息
- 假设发送方和接收方都保持存活
- 网络可能抖动(glitches,毛刺、小故障):尝试重传未传送的消息,但是最终放弃
- 某些成员没有得到消息是可以被容忍的
- 确认:
- 为每个组员发送消息
- 等待每个组员的确认
- 当有未响应成员的时候重传
- 受到(subject to)反馈内爆(feedback implosion)的影响
v. 优化确认:
i. 最简单的事情是在发送下一条消息时一直等待确认,但是会招致(incur)往返(round-trip)延迟(delay)
ii. 优化:TCP实现了前三点
- 流水线(选择重传):
- 发送多条消息,异步接收确认
- 为丢失的消息设置重传超时
- 累积确认(cumulative ACKs,回退N步):
- 在发送ACK前等待一会
- 当接收到其它的,则发送每一个ACK
- 捎带确认(Piggybacked ACKs)
- 在发送ACK的时候携带消息
- 消极确认(Negative ACKs)
- 使用序列
- 接受者要求对丢失消息的重传
- 效率更高,但要求发送者无限的缓冲消息
iii. 不可靠多播:
- 基本的多播
- 尽力而为(Hope it gets here)
6. 消息排序
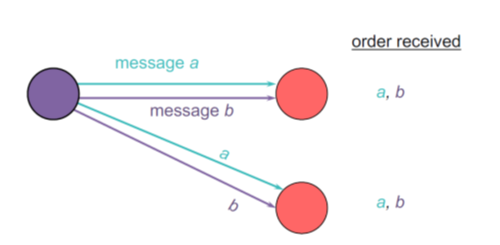
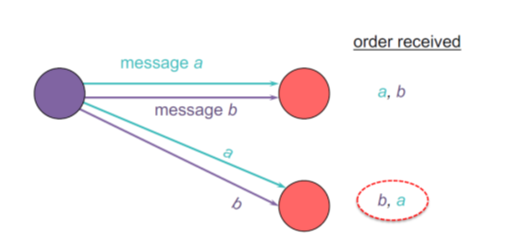
a. 消息的好坏:
- 好的排序:
- 坏的排序:
b. 发送、接收和传送
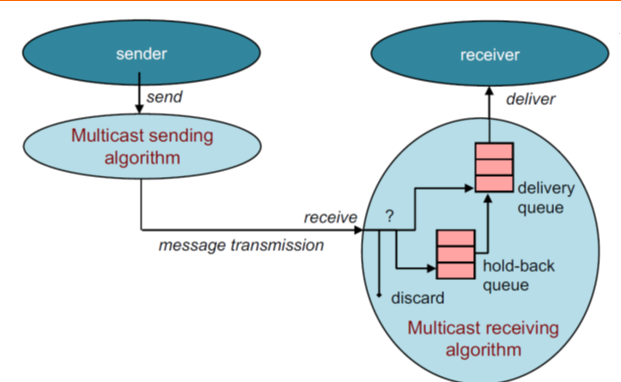
- 多播接受者算法决定何时向一个进程递送一个消息
- 消息可能被:
- 立即接收(防止到进程读取队列)
- 放置到保留队列上(因为等待较早的消息)
- 拒绝(rejected)/丢弃(discarded)(重复或者较早的不再需要的数据)
c. 时间排列:
- 所有的消息都按照确定的顺序被发送
- 假设两个事件从不发生在相同时间
- 难于实现,不可行
d. 全序
- 在所有接受者之间的一致性(consistent)顺序
- 所有消息按照相同的顺序在所有组员之内传递:
- 在发送队列中按照相同顺序排序
- 实现:
- 附加唯一的全局序列消息ID
- 接收者交付(delivers)一个消息,只在其已经接收到所有序列号更小的消息
e. 因果排序(causal ordering)
- 简介:
- 也被称之为偏序
- 原理:
- 消息被使用兰伯特(Lamport)或者向量时间戳算法排序
- 如果消息 m^′ 和 m 有因果关系,所有进程必须在 m^′ 之后发送m
- 实现:
- $P_a$ 接收从 $P_b$ 来的消息:每个进程维护优先向量(precedence vector)
- 向量被多播的发送和接收消息更新
- 算法:
f. 同步顺序(Sync Ordering)
概念:
- 消息可以以任意顺序到达
- 特定消息类型:
- 同步原语(Synchronization primitive)
- 确保所有的待定(pending)消息被交付,在任何额外的post-sync消息被接受之前
- 来自同一进程的多同步顺序的原语必须被以相同顺序交付
g. 单源FIFO排序(SSF)
概念:来自同源的消息被以发送它们的顺序传递
h. 无序多播:
- 消息可以被不同的成员以不同的顺序交付
- 每个来源的消息可以不相干
7. IP 多播路由
向一个子网的节点交付消息:发送一个多播地址
a. 如何鉴别接受者?:
在头中迭代它们?
- 如果我们不知道?
- 如果有极多的节点?
使用特定地址去鉴别一组接受者:
一组包拷贝被交付到所有与组关联的接收者
举例:
- IPV4: Class D multicast IP address
- 239.255.255.255
- IPV6:同样低位全是1
- Host Group:设置组内机器监听同一个特定地址
b. IP 多播:
i. 概念:
- 可以跨越(span)多个物理网络
- 动态成员:机器可以在任何时刻加入或者离开
- 对主机的数值没有限制
- 机器不需要是成员就可以发送消息
- 效率:包可以在必要时被复制
- 类似于IP,但是么有任何交付保证
ii. IP 多播地址:
- 地址可以被一个应用程序任意(arbitrary)的选择
- 熟知的地址被 IANA 分配
iii. IGMP
- 概念:Internet Group Management Protocol(IGMP)
- 在主机和其关联路由上的操作,为路由和主机在直接连接的网络中沟通设计
- 目标:
- 允许一个路由决定哪个网络去转发IP多播流量
- IP Protocol 2
- 三种消息类型:
- 成员关系查询(membership_query):向一个路由的所有主机接口发送消息,决定所有以加入该接口的所有多播组的主机。
- 成员关系报告(membership_report):主机响应一个查询或者初始化一个组。
- 离开组(leave_group):
- 主机表明(indicate)不再感兴趣
- 可选:路由指出主机没有回应查询
- 多播转发:
- IGMP允许主机来订阅以接收一个多播流
- 关于源:
- 对于源没有协议
- 只向 class D 发送一个消息
- 路由必须发挥效用
- 图示:
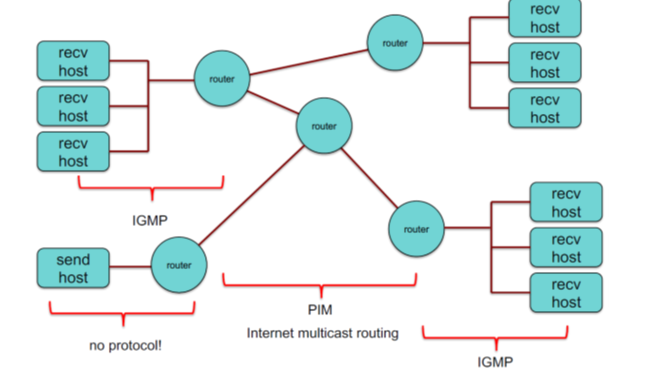
iv. PIM(Protocol Independent Multicast):
- 跨路由的包交付多播路由协议
- 其拓扑(Topology)发现由其他协议实现
- 两种形式:
- 密实模式(Dense Mode,PIM-DM)
- 稀疏模式(Sparse Mode,PIM-SM)
- 泛洪:密实模式多播
- 向所有关联路由转发多播包
- 使用生成树(spanning tree)和反向路径传播(reverse path forward,RPF)来避免回环
- 如果没有感兴趣的接收者,则反馈并切断连接(cut it off)
- 路由发送修剪(prune)消息
- 周期性的,路由发送消息来修剪状态
- 泛洪由发送路由初始化
- 反向路径传播:避免路由回环
- 只有在接收到的包通过其到发送方的最短路径接收到的时候才进行复制和转发
- 通过检查到源地址的路由检查表来进行最短路径的发现
- 优点:
- 简单
- 如果包被大多数区域需要则非常好
- 缺点:
- 浪费网络资源、额外状态,包重复多
- 向所有关联路由转发多播包
v. 稀疏模式多播:
- 每个接受者节点初始化
- 每个路由需要通过一个PIM的join请求来要求多播提要(feed)
- 位于重点的路由初始化,并发送一个 IGMP join
- 集合点(Rendezvous Point):接受者和源相遇处
- join消息传播(propagate)到预定义集合点
- 发送方仅发送到集合点
- 集合点通知该集合点的所有边缘路由
- 修剪请求会停止提要
- 优点:
- 包只去需要的地方
- 只在需要的地方的路由创建额外状态
c. 运用:
i. 早期:网络广播、NASA飞机任务(shuttle missions)、协作(collaborative)游戏
ii. 然而:
- 很少有ISP允许
- 对于用户,需要利用现有流
- 工业界拥抱(embrace)单播
iii. IPTV:
- 从早期的有线电视(cable TV)迁移到(migrated)IP交付
- 多播:
- 减少了需要的服务器
- 减少了重复的网络流
- 允许使用一个地址,将单个流的数据发送给多个订阅者
- 客户端使用IGMP:
- 订阅一个电视频道
- 改变频道
- 使用单播来点拨视频