
文章目录
分布式系统 – 一致性和复制
1. 数据的复制
a. 缘由:
- 增强(enhance)可靠性
- 提升大规模系统的性能
b. 复制必须要有一致性:
- 修改(modification)必须在多个拷贝上完成(carried out)
- 网络性能的问题
- 处理并发的需要
c. 一致性(consistency)模型:一个一致性模型是一组进程访问数据需要遵循的规则
2. 对象复制:
a. 如何保护对象不被多个客户端访问 – 同步
2.1 机制:
- 并发调用互斥位置:
- 远程对象能够处理多个并发调用(invocations)
- 远程对象的适配器被设计为可以处理多个并发调用
- 副本(replica)需要更多的同步来确保并发调用导致一致的结果:
- 分布式系统有复制感知(replication-aware)的分布式对象
- 分布式系统有副本管理,它确保调用被以正确的顺序传送到副本
3. 复制和伸缩
- 复制和缓存技术被广泛应用于伸缩性技术中
- 存在以下导致不一致的问题:
- 保持副本一致性需要使用网络
- 更新必须是原子性的(事务)
- 副本需要本同步(消耗时间)
4. 一致性模型:
4.1 数据中心(Data-Centric)一致性模型
- 图示:

- 设计:
- 通常以逻辑数据存储的方式组织,物理上使用跨机器的分布式和复制
- 每个进程可以访问自己拷贝份的数据
- 写操作被传播(propagated)到其它拷贝

4.2. 严格一致性
- 概念:任何读取都会返回相对应的(corresponding)最近写入的结果。
- 两个同时的操作,只要有写入,则被认为是冲突的
- 两个进程,在同一个数据上的操作行为:
- (a)严格一致性存储
- (b)存储并非是严格一致的
- 严格一致性是理想模型,但是并不可能在分布式系统中实现
- 其依赖于绝对全局时钟

4.3 线性(Linearizability)和序列(Sequential)一致性
- 序列一致性:
- 序列一致性是相对于严格一致性更弱的一致性
- 任何执行的结果都与在存储区的线程读写顺序和每个单独线程中程序规定的读写顺序一致。
- 没有参考操作时间
- 特点:
- 序列一致的数据存储区
- 非序列一致的数据存储区
- 线性一致性:
- 线性一致性比序列一致性更强:除其它条件相同之外,若ts_OP1 (x) < ts_OP2 (x),则操作 OP1(x) 应该在序列上前驱于OP2(x),即时间戳在前的限制性。
- 操作会接收一个全局时钟的精度,但是只有有限精度。
- 总结:
- 程序顺序必须被维护
- 数据连贯性(coherence)必须被尊重

4.4 因果一致性(Causal)
- 要求:
- 当读出现在写之后,则读可能和写存在潜在的因果联系。
- 非因果相关的操作被称为并发的。
- 必要条件:
- 存在因果关联写入操作必须被所有进程在相同顺序可见,并发写入可以不同。
4.5 FIFO一致性
必要条件:所有进程必须以相同的顺序看到一个进程中的写操作,但是不同进程看不同进程中的写操作的顺序可以不同。
4.6 弱一致性:
- 概念:引入同步变量S,其仅有一个关联操作 synchronize(S),该操作同步数据存储的所有本地拷贝,使用同步变量来部分地定义一致性被称为若一致性模型。
- 属性:
- 对数据存储所关联的同步变量的访问顺序是一致的。
- 每个拷贝完成所有先见的写操作之前,不允许对同步变量进行任何操作。
- 所有先前对同步变量执行的操作执行完毕之前,不允许对数据项进行任何读或者写操作。
4.7 释放一致性(release consistency)
- 概念:提供两种类型的同步变量:
- 属性:
- 获取 acquire 操作,适用于通知数据存储进程的临界区的操作
- 释放 release 操作,是表明进程刚刚离开临界区的操作
4.8 入口一致性(entry)
- 多个同步变量关联到每个共享数据上:
- 条件:
- 直到针对该过程执行了对受保护共享数据的所有更新之前,才允许对该过程执行同步变量的获取访问。
- 在一个进程互斥模式对同步变量的访问完成之前,其它进程不允许持有该变量,甚至即使是非互斥访问。
- 在一个对同步变量的互斥访问被完成之后,任何进程的下一个对该变量的非互斥访问都要完成,才能够执行该同步变量。
4.9 客户端中心一致性(Client Centric Consistency)
- 原因:
- 在很多情况下,仅仅在限制(restricted)的形式中并发才会出现
- 在很多应用中,大多数进程只读数据
- 某种程度上不一致是可以容许的,在某些情况下长时间的更新副本逐渐变得一致性
4.10 最终一致性(Eventual Consistency)
- 对副本数据的最佳一致性是可以的,如果客户端只访问某个相同节点
- 客户端中心一致性提供对单客户端关于其客户端数据存储的一致性。
- 解释:客户端通常使用本地副本访问分布式数据存储。更新最终会传播到其它副本。
- 单调(monotonic)读:如果某个进程读取了数据项x的值,则该进程对x进行的任何后续读取操作都将返回相同的值。
- 单调(monotonic)写:在通过同一进程对x进行后续的写操作之前,已完成对数据项x的写操作。
- 写后读:进程对数据项x的写操作效果将始终由同一进程对x的连续读取操作看到。
- 读后写:保证在相同的进程上对x的先前读取操作之后,进程对数据项x的写操作将在相同或者更新的x值上进行。
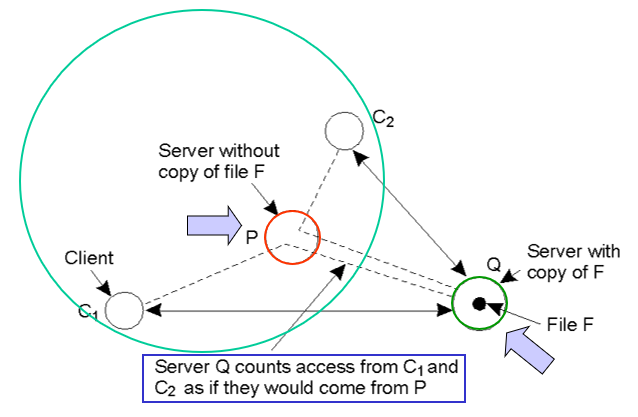
5. 分布式协议 – 副本位置
概念:何处、何时、何人的数据拷贝将被放置
种类:数据存储的不同种类副本的逻辑组织成三个同心环
5.1 服务器初始化副本 – 推缓存:
- 服务器 Q 计数对 C1 和 C2 的访问,当它们来源于无副本的服务器时。
- 示意图:
5.2 更新传播
- 传播仅仅提醒一次更新(无效协议,invalidation protocols)- R/W 比率:低
- 从一个节点到另一传输速率 – R/W 比率:高
- 传播更新操作(活复制)
5.3 拉取 vs. 推送协议 – 如何传播
- 基于推(或服务器)的协议:在一致性度高的情况下,更新被传播到其它节点,而不需要请求。
- 基于拉(或客户端)的协议:在请求时,更新被传播到其它副本。
- 混合传播:租用
- 单播(pull based approach)
- 多播(push based approach)

5.4 流行病传播:
- 概念:它和最终一致性一起为达到目标工作,更新更少的消息,感染一个服务器后其它的服务器也会被更新
- 反熵模型,三种方法:
- P 推送其更新到Q
- Q从P拉取新请求
- P和Q互相发送它们的更新
- 闲话(Gossiping)
6. 一致性协议
6.1 种类:
- 基于主服务器的协议(Primary-based protocols):数据存储中每一个数据对象x有一个关联的素数,负责协调在x上的写。
- 副本写协议(Replicated write protocols):写操作将会在多个副本上完成,而非一个。
- 缓存连贯性协议(Cache-coherence protocols):由客户端而非服务器协议。
6.2 远程写协议:
- 具有固定服务器的基于主服务器的远程写协议:所有读取和写入操作都将转发到该服务器,数据可以分发,但不可以复制
- 基于主服务器备份的协议(时间消耗):它实现了序列一致性,它完成了阻塞操作。
6.3 本地写协议:
- 基于主服务器的本地写协议:其单拷贝在进程之间迁移(数据存储的完全分布式非复制版本)。位置信息是广泛分布的数据存储中的主要问题。
- 主服务器备份的协议:主服务器在完成更新之后可以迁移。写操作作用在本地,在移动计算机断联时很有效。
6.4 副本写协议:
- 活副本:
- 每个副本拥有一个关联进程,它完成更新操作。更新是通过导致更新的写操作传播的。更新需要维护操作顺序(兰伯特时间戳或者协调者)。
- 复制调用的问题:同一个对象的多次调用会产生错误。
- 过程:
- 转发来自复制对象的调用(通过唯一ID)。
- 从复制的对象返回对复制的对象的答复。
- 基于仲裁(Quorum)的协议:
- 读写集的一个正确的选择
- 一个选择可能导致写写冲突
- 一个正确的选择(读一个,写多个)
6.5 缓存连贯性协议:缓存可以通过不同的参数分析
- 连贯侦测策略(何时)
- 在数据被访问前验证(verification)一致性
- 没有验证:数据被假设为一致的
- 在缓存被使用后验证
- 连贯强化策略(如何)
- 无缓存的共享数据
- 服务器向所有缓存发送错误的消息
- 服务器传播更新
- 写回缓存
- 客户端修改缓存数据将被转发到服务器