
文章目录
1. 原子事务(Transaction)的定义
1.1 原子事务:
- 定义:一个序列访问操作的序列
- 在以下意义(in the sense of)上是原子的
- 全或者无(All-or-Nothing)
- 序列化(Serializability)
1.2 在 RM – ODP 中事务的 ACID 属性是:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
2. 使数据库不一致的原因
- 多事务的并发访问
- 服务失败
3. 如何实现事务的原子性
3.1 概述
- 失败恢复(保证全或无)
- 意向表方法(Intention list approach)
- 影版本方法(Shadow version approach)
- 并发控制(保证序列性)
- 2-阶段锁(2-Phase Locking)
- 时间戳排序(Timestamp Ordering)
- 最优方法(Optimistic Method)
3.2 事务的失败恢复
指导思想
- 一个事务的执行有两个阶段
- 暂定阶段(tentative phase),事务体的执行
- 提交阶段(commit phase),使得暂定值持久化(permanent)
- 使得事务失败可恢复
- 将暂定的值保留在磁盘上,以免发生故障
- 当从故障中重启时,恢复数据项(恢复操作应当是幂等的,idempotent)
- 使得提交阶段可重复
4. 意向表方法
4.1 案例:
|
1 2 3 4 |
tid=OpenTrans; Twrite(tid, fd1, len1, data1) Twrite(tid, fd2, len2, data2) Close(tid) |
4.2 意向表:
|
1 2 3 |
tid, status {"Twrite, fd, pos1, len1, data1", "Twrite, fd, pos2, len2, data2"} |
4.3 意向表的实现:
- 使用意向表的事务操作
Twrite向意向表写数据Tread当意向表存在,从中读取数据CloseTrans在意向表中(或者恢复文件)向数据库执行操作
- 恢复管理者:一个当服务器从故障中重启时调用的程序
- 恢复文件:一个被恢复管理者用来将数据库还原到一致性状态的文件。
tidtransaction statusintention list
4.4 恢复案例:
- 事务 T 和 U
T transfer(A, B, $20)U transfer(C, B, $22)
- 恢复:移除被
U(p5 & p6)创建的暂定性数据并提交被T(p1 & p2)更新的数据到数据库中。
5. 影子版本方法
5.1 方法
- 当一个事务修改了一个文件或者一个数据项的时候,它创建一个影子版本的文件
Twrite和Tread的子序列被在影子版本上执行- 对于
closeTrans, 它侦测其它并发事务的版本冲突 - 如果没有冲突,影子版本将和其它已经提交的并发版本合并;否则将被中断
5.2 影子版本方法的实现
- 在事务的首个
Twrite创建文件索引块的拷贝 - 每个
Twrite操作创建影子页。索引项修改的页指向影子页 - 原始文件索引块被提交事务的新块替换(其为一个幂等的操作)
6. 可序列化,Serializability(序列等同,Serially Equivalent)
6.1 描述
- 两个事务可能互相冲突,当它们视图访问一个相同的数据项
- 只有写操作可能引发不一致性
6.2 可序列化的定义: T->U (T在U开始前完成)
U的读操作必须在T的写完成之后完成U的写操作一定会覆盖T的写操作T不会看到U的任意影响
6.3 概念和案例
- 绝对序列化执行

- 序列等价性(Serial Equivalence)
- 非序列等价

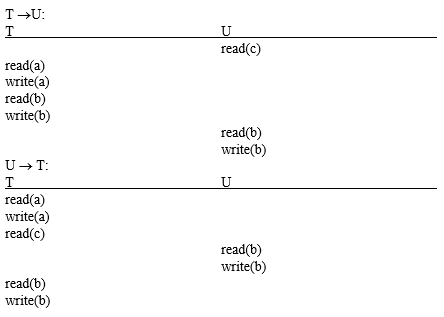

6.4 事务的可序列化
- 冲突操作:两个访问一个数据项且包括一个写的操作
- 冲突事务:两个存在冲突操作的事务
- 事务 T1 和 T2 的可序列化:对于T1和T2之间,任意两个冲突操作都遵循着相同的序列化顺序 <-> T1 和 T2 可序列化
- 可序列化的顺序:一组序列可以被序列化
- Note:可序列化通常意义上数据库一致性的最小需求
7. 两阶段锁
7.1 两阶段
- 第一阶段 – 获取锁 obtaining locks
- 第二阶段 – 释放锁 releasing locks
注意:当一个事务开始释放一个锁的时候,它不能够再应用任何锁了
7.2 为何使用两阶段锁?
- 对于简单锁可能造成死锁
- 直到 T 获得锁完成 U 都不能获得锁
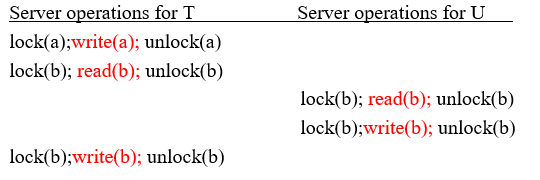

7.3 两阶段锁的可序列化
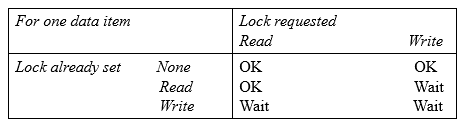
7.4 锁定的实现:
- 锁管理器:一个服务器模块。其维护一个服务器的数据项锁表。每一个锁表项有:
transaction IDdata-id IDlock typea condition variable(一个客户端等待解锁的序列)
- 锁管理器提供两个操作:
lock(trans, dataItem, lockType)lock(trans)signal the condition variablelock和unlock操作必须是原子性的
7.5 两阶段锁的死锁
- 两阶段锁内可能出现死锁
- 死锁的预防和处理
- 在事务开始的时候锁定所有待访问的数据项
- 设置等待锁的超时时间
7.6 两阶段锁的讨论
- 锁的优点
- 无中断和重启
- 易于理解和实现
- 所得缺点
- 悲观(pessimistic)
- 糟糕的表现(锁的消耗和客户端等待锁的)
- 死锁
8. 时间戳排序:
时间戳排序的可序列化性:事务以他们的开始时间来排序
8.1 重要时间戳
- 每个事务都在他们的开头被赋予了一个独特的时间戳
- 每个数据项都有其写时间(write-timestamp, wt)和读时间(read-timestamp,rt)
8.2 时间戳顺序
- 读写操作:事务的时间戳T和数据的rt、wt比较决定出操作是否被处理。
- 读规则:
- 只有事务 T 被一个更早的事务写,事务 T 才可以读
- 如果读操作被接受了,T成为一个数据暂定rt
- 写规则
- 只有事务 T 被一个更早的事务写,事务 T 才可以写
- 如果读操作被接受了,一个带有时间戳 T 暂定版本的数据被创建
- 提交 Commitment
- 当 T 被提交,它版定版本的数据和暂定版本的 rt 被持久化
- 当 T 被中止,所有被 T 创建的暂定版本的数据和 rts 都将被移除
8.3 写规则
W1:T > rt 且 T > wt,一个暂定值被创建W2:T < rt(包括暂定版本的rt)或者 T < wt,则中断
8.4 读规则
- R1:
T >= wt- 如果是一个其自身创建的暂定值,读这个暂定值
- 否则如果暂定值的时间戳早于自己,等待该暂定值被提交
- 否则立刻读数据
- R2:
T < wt,中断
8.5 事务提交
- 暂定值的提交必须等待时间更早的事务的暂定值被提交
- 事务仅等待较早的事务,来避免死锁
- 注意:所有事务都在其开始(openTrans)时被线性化
8.6 多版本时间戳排序
- 服务器保持旧的已提交版本(一个版本历史)和暂定版本的,其位于数据的版本列表中
- 一个到达过晚的读不必被拒绝,它返回拥有早于该事务最大的wt。一个读仍然需要等待一个暂定版本被提交、中断
- 写操作中没有冲突,每个写处理自己版本的数据。但是如果数据被一个更晚版本的事务读,写将会拒绝
- 一个提交不需要较早版本的事务(多版本可以共存),如果它不从较早版本的读
- 晚读/写
- 在多版本时间戳排序中,一个读操作总是会被处理(提供的老版本会被保存)
- 但是到达较晚的写操作将会被拒绝
8.7 时间戳排序的讨论
- 好处:无死锁
- 坏处:
- 额外存储的时间戳
- 可能的中断和重启
- 长事务可能阻塞(block)其它
- 案例:
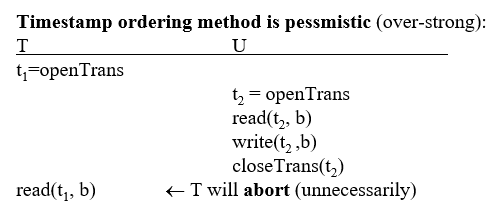
9. 时间戳排序的优化方法:
9.1 观察:
两个事务的冲突概率低;如果两个事务完全没有允许则允许继续
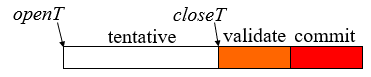
9.2 一个事务拥有三个阶段:
- 暂存 tentative、确认 validation、提交 commit
- 暂存阶段:读和写都立即返回(写作用于暂存版本)。事务的读集合(Read Set,RS)和写集合(Write Set,WS)将会被记录
- 验证阶段:检测和其它并发事务之间的冲突,决定结果的提交/中断
- 提交阶段:提交事务的暂存值
- 注意:事务按照它们 close time 的时间进行序列化
9.3 验证条件:
- 当验证 T_i 的时候,系统检查每一个和它并发的 T_j(T_i 在 T_j 的开始和结束之间开始)
- 序列化验证(Sequential Validation,overlap in tentative phase)
- $WS(T_j )∩RS(T_i )=∅$
- 并发验证(overlap in validation phase)
- $WS(T_j )∩(RS(T_i )∪WS(T_i ))=∅$
- 后提交的事务可能覆盖前提交的事务,相当于后者为前者的序列后驱
- 序列化验证(Sequential Validation,overlap in tentative phase)
- 实现细节
- validation_set:在验证时间开始时进行中的所有事务


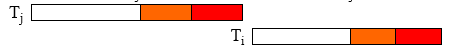

9.4 过程:
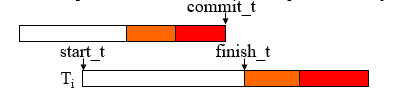
- 当 T_i 进入验证时,记录时间 finish_t ,拷贝 validation_set 并将 T_i 添加进去
- commit_t 在当前事务 start_t 和 finish_t 之间的事务在暂存阶段并发但是在验证阶段序列化
- validation_set 在验证阶段并发
- commit_t 在当前事务 start_t 和 finish_t 之间的事务在暂存阶段并发但是在验证阶段序列化
- 如果 T_i 通过验证,它进入写阶段
- $T_i$ 的 commit_t 被记录下去,并被从 validation_set 中移除
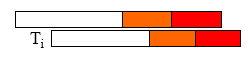
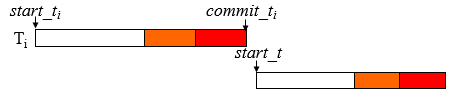
$T_i$ 需要维持多久信息?:事务的提交信息应当被保持到其它事务的验证阶段
如果 commit_t 小于 start_t 则可以移除:
9.5 优化方法的讨论
- 可序列化性:事务在结束是可以按照序列排序
- 饥饿问题:一个长事务可能一次又一次被中断
- 优点
- 优化(高并发)
- 无死锁
- 事务不会被其它阻塞
- 缺点
- 复杂
- 饥饿
- 中断和重启